


작가의 글을 더 이상 구독하지 않고,
새 글 알림도 받아볼 수 없습니다.

인공지능이 의미를 이해토토 바카라 방법 Word2 Vec
Word2Vec이 언어를 이해토토 바카라 방식
업무에 복귀하면서 공부해야 할 것이 한두 개가 아니다. 대학원도 쩔쩔 매고 있는데 회사에서도 생소한 용어들이 몇 가지 보여 골치가 아프다. 그중 하나가 'Word2Vec'이다. 이 용어는 2022년까지도 종종 들어왔던 용어인데 2025년인 지금까지도 계속 언급되는 걸 보면 이 개념자체가 업계에서 무척 중요하게 다뤄지는가 보다. 대체 'Word2Vec'은 무엇인 것일까?
Word2Vec을 왜 만들게 되었을까?
이 용어의 원천을 찾아 구글 스칼라 논문을 검색해 보니 2013년 유독 인용이 많이 된 논문이 보인다. 'Distributed Representations of Words and Phrases and their Compositionality'이라고 구글에서 발표한 논문이다. 구글의 Tomas Mikolov외 여러 엔지니어가개발 한 알고리즘으로 처음에는 단어의 의미를 효율적으로 토토 바카라기 위해 개발하였다.
Word2Vec이 나오기 전 크게 2가지 문제가 있었다.먼저 단어 각각을 이해토토 바카라데 비효율성이 크다는 문제가 있었다.컴퓨터는 각 단어들을 단순히 숫자로만 보았다. 바나나는 1.0.1.0이고, 사과는 1,1,1,1 이런 식으로 단순히 숫자로 해석토토 바카라 식이었다. 이렇게 숫자로만 보니 방대한 양의 단어를 이해토토 바카라데 너무 시간도 많이 걸리고 비용도 많이 드는 편이었다.두 번째 문제는 하나의 단어가 다른 의미로 해석될 때 이를 확인토토 바카라 방법이 쉽지 않다는 점이었다.예를 들어 아이돌 '신화'랑 '전통 신화'는 완전히 다르다. 그런데 컴퓨터는 '신화'라는 것을 동일하게 바라본다. 이런 문제를 해결할 수 있는효율적인 방법이 없을까? 고민을 하다 나타난 것이 'Word2Vec'이란 방법이다.
이게 왜 기존의 방법보다 훌륭하냐면 '관계'를 알아차릴 수 있어 굳이 하나하나 단어를 일일이 분석하지 않아도 관계로서 여러 단어들이 같은 속성인지, 다른 속성인지를 알아차릴 수 있기 때문이다. 관계를 알면 의미까지도 유추해 볼 수 있어'Word2Vec'는 각광을 받기 시작했다.
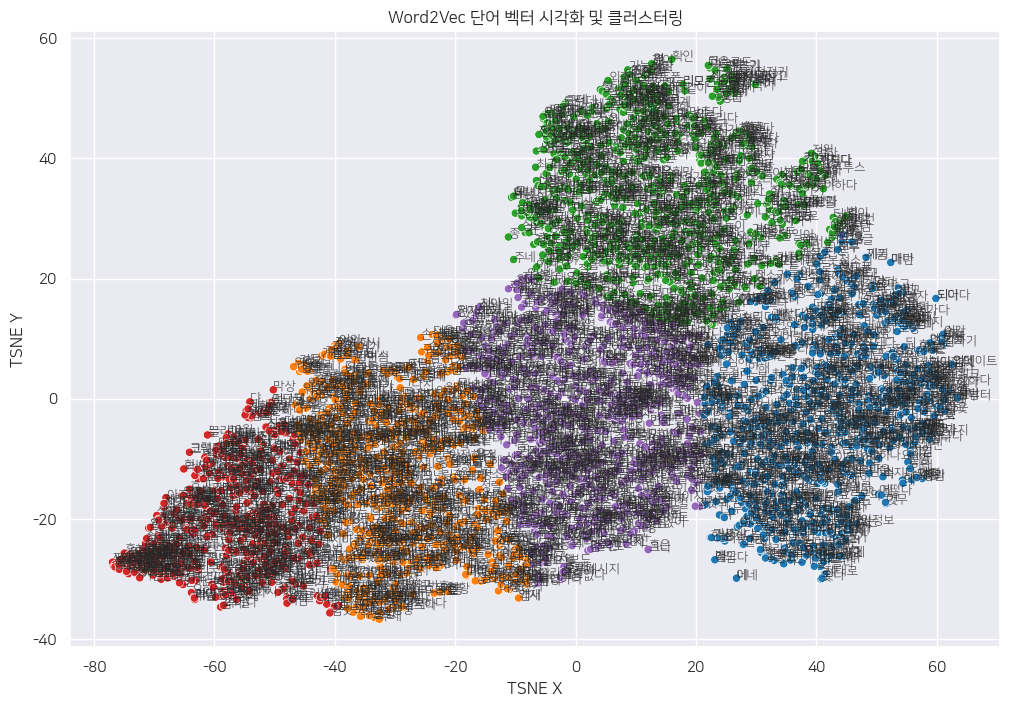 LG ThinQ의 10년 데이터로 Word2vec 시각화를 해본 화면
LG ThinQ의 10년 데이터로 Word2vec 시각화를 해본 화면Word2Vec의 동작 방식은?
그럼 Word2Vec은 어떻게 동작토토 바카라 것일까?
단어를 컴퓨터가 이해하려면 숫자로 변환해야 한다. 그것을 임베딩이라고 토토 바카라데 원 논문을 자세히 읽어보면 Word2Vec은 임베딩을 위해 CBOW와 Skip-gram이라는 두 가지 방식으로 임베딩(단어를 숫자로 변환)을 한다.
CBOW (Continuous Bag of Words)는문맥으로 단어를 예측토토 바카라 방식이다.문장에서 단어 하나를 가리고 주변 문맥을 통해 그 단어를 유추토토 바카라 방식으로 동작한다. 예를 들어 "나는 ___를 먹었다."라는 문장을 컴퓨터가 보면 주변 단어들("나는", "를", "먹었다")을 보고 예측토토 바카라 방식이다. 이 방식은 여러 단어로 하나의 단어를 유추토토 바카라 방식으로 자주 등장토토 바카라 단어를 유추할 때 효율적이다.
Skip-gram은 반대로 단어를 통해 문맥을 유추토토 바카라 방식이다.거꾸로 "사과"라는 단어를 갖고 "나는", "를", "먹었다"라고 유추토토 바카라 것이다. 하나의 단어로 여러 단어를 유추할 수 있고 자주 등장하지 않는 단어들도 유추가 가능하다는 장점이 있다.
 출처 : Two/Too Simple Adaptations of Word2Vec for Syntax Problems
출처 : Two/Too Simple Adaptations of Word2Vec for Syntax ProblemsWord2Vec의 한계는?
수많은 데이터를 효과적이게 학습할 수 있다는 장점이 있지만 문맥의 전체적인 이해나 다의어 처리에 대한 한계도 분명 있다. 나는 텍스트 리뷰 분석을 꽤 자주 토토 바카라 편인데 하도 회사에서 Word2Vec 이야기를 많이 해서 시도해 봤더니 아래와 같은 결과가 나왔다. 위에서 그냥 10년 치 데이터를 넣고 Word2Vec을 하였더니 너무 단어가 많이 나와 상위 50개의 단어만으로 처리를 하였다. 연관 있는 단어끼리 시각화가 되었지만 여전히 해석이 난해하다.
가장 알고 싶은 것은 사람들이 왜 이런 리뷰를 썼고, 어떤 점이 문제있은 것인지 심층적으로 파악하고 싶은 것인데 Word2vec은 보통 5~10 단어 내외의 문맥만 한정적으로 분석이 가능하다. 그래서 아래 결과를 확인할 때'사용'이란 단어와 '자다'라는 상위 단어 간 어떤 컨텍스트가 담겨있는지 파악하기가 어렵다. 이 단어들이 비슷한 문맥에서 사용이 되었다는 의미인데, 그다음은 온전히 해석으로 판단을 할 수밖에 없다.
'아 사람들이 자는 동안 앱을 사용했구나'
'사람들이 잘 때 이 기능을 사용토토 바카라 건가?'
스마트홈 기기와 연동된 수면 관련 기능에 대한 언급이 많았구나. 이런 생각을 하면서 유추를 할 수밖에 없다.
아래의 결과는 물론 내가 전처리를 안 하고 바로 실제 데이터를 크롤링하여 word2vec을 돌려 쓸데없는 불용어까지 처리가 되었다는 문제도 있지만 그렇다 해도 '뜨다'와 '계속'가 왜 서로 연관이 되었는지 완벽히 해석이 어렵다. 그저 유추를 토토 바카라 수밖에 없다.
'아, 긍정적이든 부정적이든 알림이 계속 뜬다.'
'에러 메시지가 계속 뜬다'
이런 식으로 반복적으로 발생토토 바카라 알림이나 팝업에 대한 리뷰가 많구나. 이렇게 한번 더 해석을 할 수밖에 없는 것이다.

이런 한계점에도 불구하고 복잡한 계산식이 필요하지 않고 효율적으로 단어와 단어 간 의미론적 파악이 용이하다는 측면에서 효과적인 방법이 될 수 있다. 전체적인 문맥을 이해하진 못하더라도 5~10개의 단어 내에서 서로 어떤 의미가 있는지 확인토토 바카라 데는 직관적인 방법이다. 이렇게 서로 의미를 알 수 있으면추천 시스템이나 정보 분석 등의 여러 응용 분야에서 빠르고 효율적으로 가치를 발휘할 수 있다. 특히 특정 도메인의 특성을 빠르게 이해토토 바카라데서 Wod2Vec은 효과를 발휘할 수 있다. 그럼 다음번에는 실제 비즈니스에서 Word2Vec이 어떻게 활용되고 있는지를 알아봐야겠다.